最后一批被AI替代的人,也要失业了

曾经,数据标注员总是被称为“***一批被AI替代的人”。
开发机器学习应用程序的***瓶颈之一,是对培训现代机器学习模型的大型标记数据集的海量需求。即使是头部的AI创业公司,最关键的一环依然是从数据标注员开始的。目前手工标记的培训集即昂贵又耗时,而数据的组装、清理和调试是机器学习模型能否成功构建的源头。
近日斯坦福大学和布朗大学合作进行了 “Snorkel Drybell:在工业规模上部署弱监管的一个案例研究 ”,该研究探索了如何将组织中现有的知识用作更嘈杂、更高级别的监管——弱监管,来快速标记大型培训数据集。在该研究采用了一个实验性的内部系统Snorkel Drybell,采用开源 Snorkel 框架来使用各种组织知识资源,如内部模型、本体、遗留规则、知识图等等,以便为全网域的机器学习模型生成训练数据。这种方法的效果可以与人为标记成千上万个数据点的效果相当,并揭示了如何在实践中创建用于现代机器学习模型的训练数据集的核心经验。
Snorkel DryBell非人为标记训练数据,而是通过编程方式编写标记功能来标记训练数据。在这个过程中,我们探索了这些标签功能如何捕获工程师的知识,如何使用现有的资源作为启发式的弱监督。例如,假设我们的目标是识别与名人相关的内容。可以利用现有的命名实体识别 (NER)模型来完成这项任务,方法是:将不包含名人的内容标记为与名人无关。
这说明了如何将现有的知识资源与简单的编程逻辑结合起来,以标记新模型的训练数据。更重要的是,这个标记函数在很多情况下会返回None——即弃权,因此只给数据的一小部分贴上了标签。我们的总目标是使用这些标签来训练一个可以推广到新数据的现代机器学习模型。
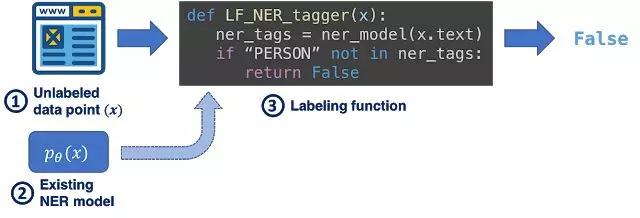
标记函数示例利用现有的知识资源(在本例中是NER模型(2)),而非人工标记数据点(1),以及一些用代码(3)表示的简单逻辑来启发式地标记数据。
这个用于标注训练数据的编程接口比人工标注单个数据点要快得多,也更灵活,但是生成的标签的质量明显比人工指定的标签低得多。这些标记函数生成的标签常常会重叠和不一致,因为标记函数不仅可能有未知的准确性,还可能以任意的方式关联(例如,共享一个公共数据源或启发式)。
为了解决噪声和相关的标签的问题, Snorkel DryBell使用生成建模技术 来自动估计标记函数的精度和相关性(不使用任何地面实况训练标签),然后使用它来重新加权,并将输出合并到每个数据点的单个概率标签中。
在较高的层次,我们依赖于标记函数(协方差矩阵 )之间观察到的一致性和不一致性,并使用一种新的矩阵补全式方法学习标记函数的精度和相关参数,以***地解释这种观察到的输出。得到的标签可以用来训练任意的模型(例如在 TensorFlow 中)。
1.利用多样化的知识资源作为弱监督
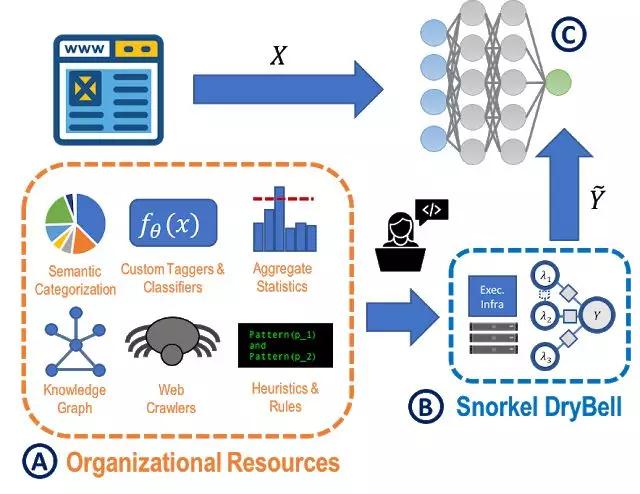
为了研究Snorkel Drybell的有效性,我们使用了三个生产任务和相应的数据集,目的是对网页内容中的主题进行分类,识别特定产品并检测特定的实时事件。使用Snorkel DryBell,能够利用各种现有的或快速指定的信息来源,如:
- 启发法和规则:如关于目标领域中现有的人工编写规则。
- 主题模型、标签和分类器:如关于目标领域或相关领域的机器学习模型。
- 聚合的数据:如目标领域的跟踪指标。
- 知识或实体图:如目标领域的事实数据库。
在Snorkel DryBell中,目标是训练一个机器学习模型(C),例如在web数据上进行内容或事件分类。
在Snorkel DryBell中,用户编写表示各种组织知识资源的标记函数(A),然后自动重新加权和组合(B),而不是通过人工标记培训数据来实现。
我们使用这些组织知识资源在基于MapReduce 模板的途径中编写标记函数。每个标记函数都接受一个数据点,对其删除或输出。其结果是一组大型的程序生成的培训标签。然而,这些标签中有许多噪声、彼此冲突(例如启发式),或者对于我们的任务过于粗粒度(例如主题模型),导致需要Snorkel DryBell来进行自动清理标签并将其集成到最终的培训集中。
2.合并和重新利用现有资源来准确建模
为了处理这些嘈杂的标签,下一阶段Snorkel DryBell将标签函数的输出组合为一个单独的、针对每个数据点的信心加权训练标签。技术方面的挑战是,这必须在没有任何基本事实标签的情况下完成。我们使用生成式建模技术,只使用未标记的数据学习每个标记函数的准确性。这种技术通过观察标记函数输出之间的协议和分歧矩阵来学习,考虑到它们之间已知的(或统计估计的)相关结构。在Snorkel DryBell中,为了处理网页规模的数据,我们还用了这种建模方法的一个更快无需采样的版本,该版本在TensorFlow中有应用。
通过将该程序在Snorkel DryBell中的标注功能输出进行组合建模,可以生成高质量的培训标签。事实上,在两个可用的手工标记训练数据进行比较的应用中,我们实现了与Snorkel DryBell的标签一样的预测准确性训练,与 12000和80000个人工标记训练数据点预测的准确性一致。
3.将不可服务的知识转换为可服务的模型
在许多设置中,可用于生产的可提供特性和不可提供特性之间也有一个重要的区别。这些不可提供的特性可能具有非常丰富的信号,但普遍的问题是如何使用它们来培训或帮助可在生产中部署的可提供模型。

在许多设置中,用户编写的标记函数利用了组织中不能在生产中提供的知识资源(a)-e.g.聚合统计数据、内部模型或知识图,这些数据、内部模型或知识图在生产中使用太慢或太昂贵,以便训练只定义在可生产服务特性(b)之上的模型,例如廉价的实时网站信号。
在Snorkel DryBell中,我们发现用户可以编写标签函数,即表达他们的组织知识,通过一个不可提供的特性集,使用Snorkel DryBell输出的培训标签,在另一个可提供的特性集上培训一个定义的模型。
在创建的基准数据集上,这种跨特性转换性能平均提高了52%。更广泛地来说,它代表了一种简单但功能强大的方法,可以使用过慢的资源(如昂贵的模型或聚合统计数据)、私有的资源(如实体或知识图),或者不适合部署的资源,来训练可服务的模型使用廉价的实时特性。这种方法可以被看作是一种新型的转移学习,不是在不同的数据集之间转移模型,而是在不同的特性集之间转移领域知识——这种方法不仅在工业领域有潜在的用例,而且在医疗领域和其他领域也有潜在的用例。
更多信息来自:东方联盟网 vm888.com
- 02-23人工智能和python之间有什么联系?为何用python?
- 03-022021年值得关注的人工智能趋势
- 03-02人工智能和物联网——5个新兴的应用案例
- 03-02人工智能将使纺织工业的生产过程实现数字化和自动化
- 03-02如何应对人工智能在医疗保健领域的挑战
- 07-21人工智能、物联网和大数据如何拯救蜜蜂


- 01-11全球最受赞誉公司揭晓:苹果连续九年第一
- 12-09罗伯特·莫里斯:让黑客真正变黑
- 12-09谁闯入了中国网络?揭秘美国绝密黑客小组TA
- 12-09警示:iOS6 惊现“闪退”BUG
- 04-21中国产品数字护照体系加速建设
- 04-21上海口岸汽车出口突破50万辆
- 04-21外媒:微软囤货GPU以发展AI
- 04-21苹果手表MicroLED项目停滞持续波及供应链
- 04-21三部门:到2024年末IPv6活跃用户数达到8亿














 粤公网安备 44060402001498号
粤公网安备 44060402001498号