我研究了最热门的200种AI工具,却发现这个行业有点饱和
在 LinkedIn 上,很多你申请的机器学习职位都有超过 200 名竞争者。在 AI 工具上人们也有这么多选择吗?
为了完整了解机器学习技术应用的现状,毕业于斯坦福大学,曾就职于英伟达的工程师 Chip Huyen 决定评测目前市面上所有能找到的 AI / 机器学习工具。
在搜索各类深度学习全栈工具列表,接受人们的推荐之后,作者筛选出了 202 个较为热门的工具进行评测。最近,她的统计结果让机器学习社区感到有些惊讶。

首先要注意的是:
这一列表是在 2019 年 11 月列出的,最近开源社区可能会有新工具出现。
有些科技巨头的工具列表庞大,无法一一列举,比如 AWS 就已经提供了超过 165 种机器学习工具。
有些创业公司已经消失,其提出的工具不为人们所知。
作者认为泛化机器学习的生产流程包括 4 个步骤:
项目设置
数据 pipeline
建模和训练
服务
作者依据所支持的工作步骤将工具进行分类。项目设置这一步没有算在内,因为它需要项目管理工具,而不是机器学习工具。由于一种工具可能不止用于一个步骤,所以分类并不简单。「我们突破了数据科学的极限」,「将 AI 项目转变为现实世界的商务成果」,「允许数据像您呼吸的空气一样自由移动」,以及作者个人最喜欢的「我们赖以生存和呼吸的数据科学」,这些模棱两可的表述并没有让问题变得更简单。
工具的时间演变历程
作者追溯了每种工具发布的年份。如果是开源项目,则查看首次提交,以查看项目开始公开的时间。如果是一家公司,则查看该公司在 Crunchbase 上的创办年份。然后她绘制了随着时间的推移,每个类别中工具数量的变化曲线。具体如下图所示:
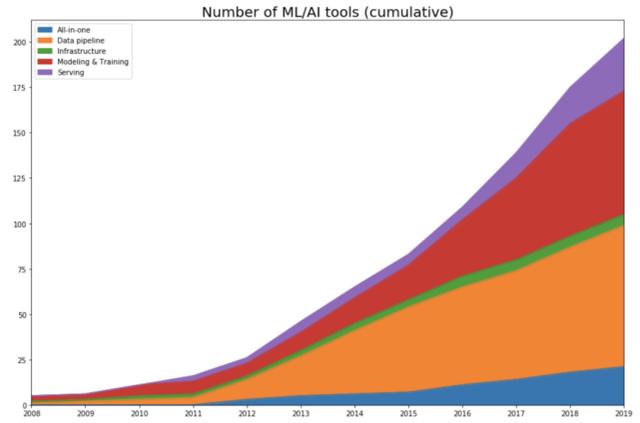
不出所料,数据表明,随着 2012 年深度学习的复兴,该领域才开始呈爆炸式增长。
AlexNet 之前(2012 年之前)
直到 2011 年,该领域仍然以建模训练工具为主导,有些框架(比如 scikit-learn)仍然非常流行,有些则对当前的框架(Theano)产生了影响。2012 年以前开发出来且至今仍在使用的一些工具要么完成 IPO(如 Cloudera、Datadog 和 Alteryx),要么被收购(Figure Eight),要么成为受社区欢迎并积极开发的开源项目(如 Spark、Flink 和 Kafka)。
开发阶段(2012-2015)
随着机器学习社区采用「let’s throw data at it」的方法,机器学习空间就变成了数据空间。当调查每个类别中每年开发出的工具数量时,这一点更加明显。2015 年,57%(82 个工具中有 42 个)的工具都是数据 pipeline 工具。具体如下图所示:
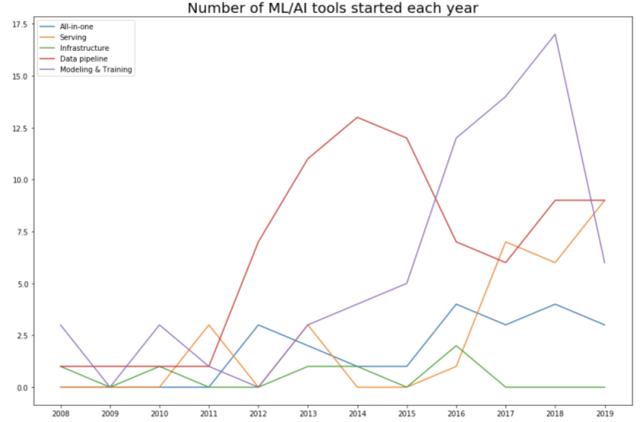
生产阶段(2016 年至今)
每个人都知道越基础的研究越重要,但大多数公司都无法支持研究人员进行纯技术方向的探索——除非能够看到短期商业利益。随着机器学习研究、数据和已训练模型数量的增多,开发者和机构的需求增加,市场对于机器学习工具的需求也有了巨大的增长。
2016 年,谷歌宣布将神经机器学习技术应用到谷歌翻译中,这是深度学习在现实世界里首次落地的重要标志。
这一全景图仍不完整
AI 创业公司现在已经有很多了,但它们大多数都面向技术的落地(提供面向消费者的应用),而不是提供开发工具(如向其他公司售卖框架和软件开发包)。用风险投资的术语来说,大多数初创公司都是垂直 AI 领域里的。在福布斯 2019 年公布的 50 大 AI 初创公司里,只有 7 家是以机器学习开发工具为主业的。
对于大多数人来说,应用更为直观。你可以走进一家公司说:「我们可以让你们的一半客服工作实现自动化。」工具实现的价值总是间接的,但又深入整个生态系统。在一个市场中,很多公司都可以提供相同的应用,但其背后用到的工具却只有寥寥几种。
经过大量搜索和比对,在这里作者只列出了 200 余个 AI 工具,相对于传统计算机软件工程来说这个数字很小。如果你想评测传统的 Python 应用开发,你可以用谷歌几分钟内找出至少 20 个工具,但如果你想试试机器学习模型,事情就完全不一样了。
机器学习工具面临的问题
很多传统的软件工具都可以用于开发机器学习应用。但是在机器学习应用中,也有很多挑战是独有的,需要特殊的工具。
在传统软件开发流程中,写代码是最难的一步,但在机器学习工作中,写代码只是整个流程中耗费精力较小的一部分。开发一个可以带来很大性能提升,并且在现实世界中可以落地的新模型非常耗费时间和资金。大多数公司都会选择不去开发新模型,而是直接拿来就用。
对于机器学习来说,使用最多 / 最好数据的应用总会获胜。所以与其专注于提升深度学习算法,大多数公司都会花费大量时间提升数据的质量。因为数据的变化总是很快,机器学习应用也需要快速的开发和部署。在很多例子中,你甚至需要每天都部署新的模型。
此外,ML 算法的规模也是一个问题。预训练的大规模 BERT 模型具有 3.4 亿参数,大小为 1.35GB。即使 BERT 模型可以拟合手机等消费类设备,但在新样本上运行推理所耗费的大量时间就使其对于现实世界的众多应用毫无用处。
试想,如果自动补全模型提示下一个字符所花费的时间比用户自己键入的时间还要长,那么有什么必要用这个模型呢?
Git 通过逐行的差异比较实现了版本控制,因而对大多数传统软件工程程序的效果很好。但是,Git 并不适用于数据库或者模型检查点的版本控制。Panda 对大多数传统数据框操作的效果很好,但在 GPU 上不起作用。
CSV 等基于行的数据格式对于使用较少数据的应用有很好的效果。但是,如果你的样本具有很多特征,并且你只想利用其中的一个子特征,则使用基于行的数据格式依然需要你加载所有的特征。PARQUET 和 OCR 等柱状文件格式针对这种用例进行了优化。
ML 应用面临的一些问题如下所示:
监测:怎么知道你的数据分布已经改变以及需要重新训练模型?
数据标注:如何快速地标注新数据,或者为新模型重新标注现有数据?
CI/CD 测试:由于你不能花几天的时间等着模型训练和收敛,所以如何运行测试以确保每次改变后模型像期望地那样运行?
部署:如何封装和部署新模型或者替换现有模型?
模型压缩:如何压缩 ML 模型使其拟合消费类设备?
推理优化:如果加速模型的推理时间?是否可以将所有操作融合在一起?是否可以采用更低精度?缩小模型或许可以加速推理过程。
边缘设备:硬件运行 ML 算法速度快且成本低。
隐私:如何在保护隐私的同时利用用户数据来训练模型?如何使流程符合《通用数据保护条例》(GDPR)?
在下图中,作者根据开发工具能够解决的主要问题列出了它们的数量:
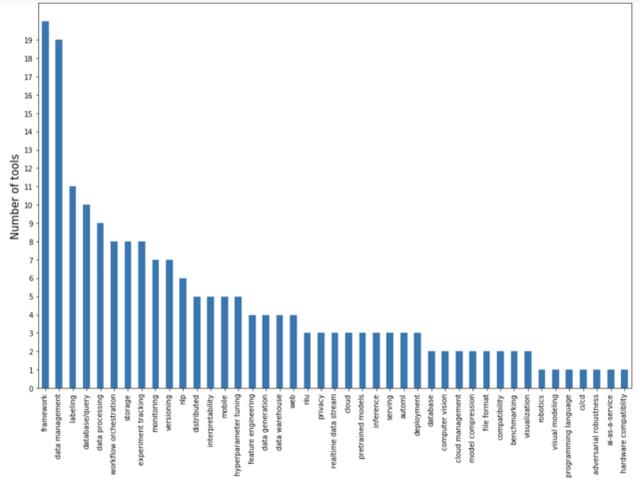
一大部分集中在数据 pipeline,包括数据管理、贴标签、数据库 / 查询、数据处理和数据生成。数据 pipeline 工具可能也想成为一体化平台(all-in-one platform)。由于数据处理是项目中最耗费资源的阶段,一旦有人在你的平台上放置他们的数据,那就很有可能给他们提供预构建或预训练的模型。
建模和训练工具大多是框架。当前深度学习框架之争有所平静,主要集中在 PyTorch 和 TensorFlow 这两者之间,以及基于这两者解决 NLP、NLU 和多模态问题等特定任务的更高级的框架。分布式训练领域也有一些框架。还有一个出自谷歌的新框架 JAX,每个讨厌 TensorFlow 的谷歌员工都力捧这个框架。
存在一些用于实验追踪的独立工具,一些流行深度学习框架还有内置的实验追踪功能。超参数调整很重要,所以出现专门用于超参数调整的工具并不奇怪,但是它们似乎没有一个流行起来。因为超参数调整的瓶颈不是设置,而是运行它所需的算力。
尚未解决但最令人兴奋的问题在部署和服务空间中。缺少服务方法的原因之一是研究人员与生产工程师之间缺乏沟通。在有能力进行人工智能研究的公司(常常是大公司),研究团队与部署团队是分开工作的,两个团队仅通过 P 打头的经理:产品经理、程序经理、项目经理互相交流进行沟通。而员工可以看到整个堆栈的小公司就会受到即时产品需求的限制。
只有少数几家初创公司能够缩小差距,这些公司通常是由已有成就的研究人员创建,并且有足够的资金雇佣优秀的工程师。而这样的初创公司将会占据人工智能工具市场很大一部分。
开源和开放内核(open-core)
作者选择的 202 种工具中有 109 种是开源软件(Open Source Software, OSS),并且没有开源的工具也常常与其他开源工具绑在一起。
开源软件的出现和发展由多种原因促成,以下是所有开源软件支持者谈论数年的一些原因,包括透明度、协作、灵活性以及合乎伦理道德。客户可能不希望使用无法获取源代码的新工具。否则,如果不开放源代码的工具无法使用,则必须重写代码。这是初创公司经常出现的状况。
开源软件并不意味着非盈利和免费,开发者有其更深远的目的。需要看到,开源软件的维护耗时且花费不菲。传闻 TensorFlow 团队的成员数接近 1000 人。一家企业提供开源软件肯定有其商业目的,举例而言,越来越多的人使用某家公司的开源软件,那么该公司的名头就会越来越响,人们也就更加信任这家公司的专业技术,最终可能会购买他们的专有工具,甚至加入他们的团队。
这样的例子比比皆是。谷歌不遗余力地推广他们的工具,其目的是想用户使用其云服务。英伟达维护 cuDF,旨在售卖更多的 GPU。Databricks 免费提供 MLflow,但也售卖他们的数据分析平台。
此外,网飞公司最近成立了专门的机器学习团队,并推出了自己的 Metaflow 框架,从而也加入到了机器学习(ML)的发展大潮中,以吸引人才。Explosion 免费提供 SpaCy,但同时对 Prodigy 收费。HuggingFace 是一个特例,它免费提供 transformer,但不清楚究竟如何盈利。
随着软件开源成为一种标准,初创公司找到一种行之有效的商业模式变得很困难。任何刚起步的工具类公司都必须与现有开源工具竞争。所以,如果初创公司选择开源内核的商业模式,则必须决定开源软件中涵盖哪些功能,付费版本中包含哪些内容才不显得贪得无厌,以及如何让免费使用工具的用户开始付费。
未来展望
关于 AI 泡沫是否破裂的讨论此起彼伏。很大一部分的 AI 投资流向了自动驾驶汽车,但我们已了解完全自动驾驶的车辆离落地应用还有很长的路要走,一些人猜测投资者将会对 AI 完全丧失信心。
谷歌暂停了 ML 研究人员的招聘,优步也解雇了 AI 团队中一半的研究人员。这些决策都是在新冠肺炎爆发之前做出的。此外,有传言称,由于选择攻读机器学习的人数太多了,市场上 ML 的工作需求却远远少于掌握 ML 技术的人才。
那么问题来了,现在进入 ML 领域还是好时机吗?不可否认,AI 炒作确实存在,在某种程度上,这种热度需要「降温」。这一点可能已经发生了。然而,作者并不认为 ML 会消失。可能越来越少的企业能够支撑得起 ML 研究,但依然会有企业需要工具将它们的 ML 付诸生产。
由此,如果必须在工程和 ML 两者之间选择,作者建议选择工程。优秀的工程师学习 ML 知识更加容易,但 ML 专家想要成为优秀的工程师就比较困难了。如果可以成为一位能够构建优秀 ML 工具的工程师,那真是再好不过了!
更多信息来自:东方联盟网 vm888.com
- 02-23人工智能和python之间有什么联系?为何用python?
- 03-022021年值得关注的人工智能趋势
- 03-02人工智能和物联网——5个新兴的应用案例
- 03-02人工智能将使纺织工业的生产过程实现数字化和自动化
- 03-02如何应对人工智能在医疗保健领域的挑战
- 07-21人工智能、物联网和大数据如何拯救蜜蜂


- 01-11全球最受赞誉公司揭晓:苹果连续九年第一
- 12-09罗伯特·莫里斯:让黑客真正变黑
- 12-09谁闯入了中国网络?揭秘美国绝密黑客小组TA
- 12-09警示:iOS6 惊现“闪退”BUG
- 07-17亚马逊海外购上线顺丰国际直邮服务
- 07-17Omdia预测XR显示屏市场短期稳定,长期增长潜
- 07-17微软Word升级Draft AI:支持智能改写、扩写
- 07-17特斯拉Optimus人形机器人取得显著进展,国内
- 07-17vivo智能车载系统升级,新增视频类应用














 粤公网安备 44060402001498号
粤公网安备 44060402001498号