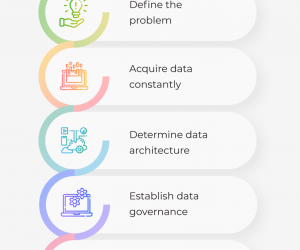
微软新研究:无人机获推理能力,看图就能做出决策

雷锋网注:图自微软官网
一般来说,人类通过感知来作出相应的决策,比如因为看到障碍物而选择避让。
尽管这种“从感知到动作”的逻辑已经应用到了传感器和摄像头领域,并成为了当前一待机器人自主系统的核心。但是,目前机器的自治程度远远达不到人类根据视觉数据而作出决策的水平,尤其是在处理第一人称视角(FPV)航空导航等开放世界感知控制任务时。
不过,微软近日分享的新的机器学习系统这一领域带来了新的希望:帮助无人机通过图像推理出正确的决策。
微软从第一人称视角(FPV)无人机竞赛中获得启发,竞赛中的操作员可以通过单眼摄像头来规划和控制无人机的运行路线,从而大大降低发生危险的可能性。因此,微软认为,这一模式可以应用到新的系统当中,从而将视觉信息直接映射成实施正确决策的动作。
具体来说,这个新系统明确地将感知组件(理解“看到的”内容)与控制策略(决定“做什么”)分开,这样便于研究人员调试深层神经模型。模拟器方面,由于模型必须能够分辨出模拟和真实环境之间细微的差异性,微软使用了一种名为“AirSim”的高保真模拟器对系统进行训练,然后不经修改,直接将系统部署到真实场景里的无人机上。

雷锋网注:上图为微软在测试中使用的无人机
他们还使用了一种称为“CM-VAE”的自动编码器框架来紧密连接模拟与现实之间的差异,从而避免对合成数据进行过度拟合。通过 CM-VAE 框架,感知模块输入的图像从高维序列压缩成低维的表示形式,比如从 2000 多个变量降至 10 个变量,压缩后的像素大小为 128x72,只要能够描述其最基本的状态就行。尽管系统仅使用了 10 个变量对图像进行编码,但解码后的图像为无人机提供了“所见场景”的丰富描述,包括物体的尺寸、位置,以及不同的背景信息。而且,这种维度压缩技术是平滑且连续的。
为了更好地展示这一系统的功能,微软使用带有前置摄像头的小型敏捷四旋翼无人机进行了测试,试图让无人机根据来自 RGB 摄像机的图像来进行导航。
研究人员分别在由 8 个障碍框组成的长达 45 米的 S 型轨道上,以及长达 40 米的 O 型轨道上对装载系统的无人机进行了测试。实验证明,使用 CM-VAE 自动编码框架的表现比直接编码的表现要好很多。即便是在具有强烈视觉干扰的情况下,这个系统也顺利地完成了任务。

雷锋网注:上图为测试场地的侧视图和俯视图
微软方面声称:
在模拟训练阶段,在无人机从未“见过”的视觉条件下对其进行测试,我们将感知控制框架发挥到了极致。
在通过仿真训练后,这个系统能够独立在现实世界充满挑战的环境下进行“自我导航”,非常适合部署在搜索和救援任务中。该项研究的参与者表示,该系统在实际应用中将展现出巨大的潜力——尽管年龄,大小,性别,种族和其他因素有所不同,但自主搜索和救援机器人能够更好地识别出人类,并帮助人类。
更多信息来自:东方联盟网 vm888.com
- 02-23人工智能和python之间有什么联系?为何用python?
- 03-022021年值得关注的人工智能趋势
- 03-02人工智能和物联网——5个新兴的应用案例
- 03-02人工智能将使纺织工业的生产过程实现数字化和自动化
- 03-02如何应对人工智能在医疗保健领域的挑战
- 07-21人工智能、物联网和大数据如何拯救蜜蜂


- 01-11全球最受赞誉公司揭晓:苹果连续九年第一
- 12-09罗伯特·莫里斯:让黑客真正变黑
- 12-09谁闯入了中国网络?揭秘美国绝密黑客小组TA
- 12-09警示:iOS6 惊现“闪退”BUG
- 04-21中国产品数字护照体系加速建设
- 04-21上海口岸汽车出口突破50万辆
- 04-21外媒:微软囤货GPU以发展AI
- 04-21苹果手表MicroLED项目停滞持续波及供应链
- 04-21三部门:到2024年末IPv6活跃用户数达到8亿














 粤公网安备 44060402001498号
粤公网安备 44060402001498号