一个基于MySQL的Key-List存储方案
目标:
Key-List模型、千亿万亿级别、分布式、可扩展、确保一定的性能、高可用
基本思想:
1、 同一个key对应的list尽量集中化
2、 通过表升级、表分裂限制表的大小
3、 参考HBase的方案管理表
表升级、分裂方案:
以典型数据<uid,mid>(联合主键)为例,假设每条记录40字节
确保每个表最大条数1千万(每个数据文件不要超过400M,或者可以限制最大条数1百万,最多40M),设置mysql每张表一个表空间
通过两个条件来限制:uid个数、uid中最多的mid个数 相乘小于1kw
四个级别的表:
1级:十万用户 100条记录,如果用户数超过十万则分裂为两个或多个1级表;如果有用户记录数大于100则移动到最小的2级表中。(分裂或升级均凌晨闲时执行,升级优先)
2级:一万用户 1000条记录,同上
3级:一千用户 10000条记录,同上
4级:一百用户以下 100000条记录以上
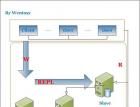
结构图和各部分的功能
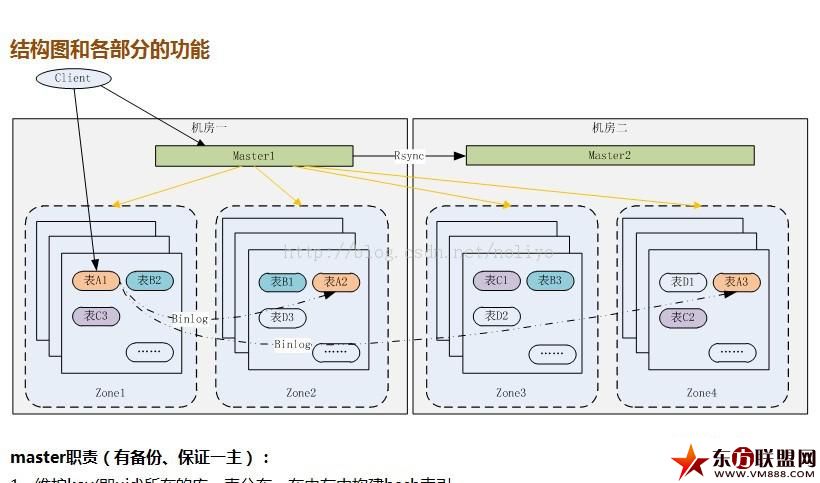
master职责(有备份、保证一主):
1、维护key(即uid)所在的库、表分布,在内存中构建hash索引
2、协调数据容量负载均衡,写表尽量分散在各zone中
3、感知节点,如果有节点增删,做相应的操作
zone职责:
负责监控表,实施表的分裂,分裂在本zone完成,期间需要和mater进行通信,完成之后其他zone进行备份
分裂操作(太复杂,没想太清楚):
分裂点界定:对uid按照mid从多到少排序,当相加个数大于总个数一半时为拆分点
拆分时选择某一个从表,通知master对此表加读锁并记录同步日志点p,拆分过程不能分配读写操作,拆分完毕后将日志点p后的数据同步至两个新表,同步完毕通知master将写全部映射到新表,其他的备份通过主从方式自动更新为两个表,或者使用缓冲表or缓冲队列来实现
分裂之后的数据副本:由master决定放在比较空闲的zone中
升级操作:
由master协调,具体升级在各zone内部进行,不涉及表数量的修改,相对分裂简单许多,但是涉及key的分布修改
读写操作:
先从master中获取对应表位置
读数据:就近读,优先读取本机房的主表所在节点,不成功则取其他
写数据:只写主表,可能不是最近的机房,有单点问题,如果挂掉,通知master更换主,此过程过长则通过缓冲队列解决
加入新机器:
计算各节点的表个数,数据最大的M个节点各分一部分表给新加机器,完毕后通知master
某一机器挂掉:
找到表最小的几个机器,对挂掉节点的表数据按照一定规则复制过去
或者等待DBA处理,不需要立即处理
通知master
难点(不过解决起来有参照,例如HBase):
自动化的表分裂、升级过程复杂
表管理复杂
如何保证读写服务正常、数据一致性
- 10-26高手浅谈MySQL数据库的几个安全问题
- 10-26MySQL False 黑客注入及技巧总结
- 02-2514种最好方法保护MySQL全面安全
- 12-23mysqltoolkit用法[备忘]
- 12-23一个基于MySQL的Key-List存储方案
- 12-21ODBC中遇到的错误
- 12-21使用mysql遇到的问题
- 12-21PAIP.MYSQLSLEEP连接太多解决

- 01-11全球最受赞誉公司揭晓:苹果连续九年第一
- 12-09罗伯特·莫里斯:让黑客真正变黑
- 12-09谁闯入了中国网络?揭秘美国绝密黑客小组TA
- 12-09警示:iOS6 惊现“闪退”BUG
- 07-17亚马逊海外购上线顺丰国际直邮服务
- 07-17Omdia预测XR显示屏市场短期稳定,长期增长潜
- 07-17微软Word升级Draft AI:支持智能改写、扩写
- 07-17特斯拉Optimus人形机器人取得显著进展,国内
- 07-17vivo智能车载系统升级,新增视频类应用
![mysqltoolkit用法[备忘]](/d/file/database/MYSQL/2013-12-23/04bc6d6d44f8997289d0a8a3716d5896.png)






 粤公网安备 44060402001498号
粤公网安备 44060402001498号