数据库优化六 SQL优化之SELECT优化 filesort
在执行计划中,可能经常看到有Extra列有filesort,这就是使用了文件排序,这当然是不好
的,应该优化,但是,了解一下他排序的原理也许很有帮助,下面看一下filesort的过程:
1、根据表的索引或者全表扫描,读取所有满足条件的记录
2、对与每一行,存储一对儿值到缓冲区,一个是排序的索引列的值,即order by用到
的列值,和执向该行数据的行指针,缓冲区的大小为sort_buffer_size大小
3、当缓冲区满后,运行一个快速排序(qsort)来将缓冲区中数据排序,并将排序完的
数据存储到一个临时文件,并 保存一个存储块儿的指针,当然,如果缓冲区不满,
则不会重建临时文件了
4、重复以上步骤,直到将所有行读完,并建立相应的有序的临时文件
5、对块级进行排序,这个类似与归并排序算法,只通过两个临时文件的指针来不断交换
数据,最终达到两个文件,都是有序的
6、重复5,直到所有的数据都排序完毕
7、采取顺序读的方式,将每行数据读入内存,并取出数据传到客户端,这里读取数据时
并不是一行一行读,读如缓存大小由read_rnd_buffer_size来指定
这就是filesort的过程,采取的方法为:快速排序 + 归并排序,但有一个问题,就是,一行数据会
被读两次,第一次是where条件过滤时,第二个是排完序后还得用行指针去读一次,一个优化的
方法是,直接读入数据,排序的时候也根据 这个排序,排序完成后,就直接发送到客户端了,
过程如下:
1、读取满足条件的记录
2、对于每一行,记录排序的key和数据行位置,并且把要查询的列也读出来
3、根据索引key排序
4、读取排序完成的文件,并直接根据数据位置读取数据返回客户端,而不是去访问表
这也有一个问题:当获取的列很多的时候,排序起来就很占空间,因此,max_length_for_sort_data
变量就决定了是否能使用这个排序算法
建议:
1、对于使用filesort的慢查询,可以改小一些max_length_for_sort_data来使用第一个方法
2、对于想要加快order by 的顺序,有以下一些策略:
a、增加sort_buffer_size的大小,如果大量的查询较小的话,这个很好,就缓存中就搞定了
b、增加read_rnd_buffer_size大小,可以一次性多读到内存中
c、列的长度尽量小些
d、改变tmpdir,使其指向多个物理盘(不是分区)的目录,这将机会循环使用做为临时文件区
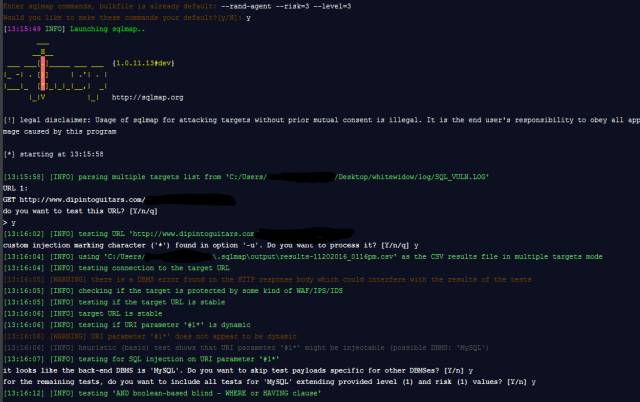
- 10-26Whitewidow SQL漏洞扫描工具演示
- 10-26SQL黑客注入防御与绕过的多种姿势
- 12-23SQLServer数据库操作总结(sql语法的使用)
- 12-21C#连接Sqlite
- 12-21ORACLE数据库学习之SQL性能优化详解
- 12-21解决SQLSERVER2008数据库日志文件占用硬盘空间问题
- 01-11全球最受赞誉公司揭晓:苹果连续九年第一
- 12-09罗伯特·莫里斯:让黑客真正变黑
- 12-09谁闯入了中国网络?揭秘美国绝密黑客小组TA
- 12-09警示:iOS6 惊现“闪退”BUG
- 05-06TCL科技:预计大尺寸面板价格上涨动能有望延
- 05-06新加坡电信Optus任命新首席执行官以重建品牌
- 05-06微软宣布为消费级用户账户提供安全密钥支持
- 05-06当好大数据产业“守门员”(筑梦现代化 共绘
- 04-29通用智能人“通通”亮相中关村论坛
![[SQLServer]发送HTML格式邮件](/d/file/database/SQLServer/2013-12-21/e4cf8ee11e5808af02776facb796ca42.jpg)







 粤公网安备 44060402001498号
粤公网安备 44060402001498号