酷极了!5分钟用Python理解人工智能优化算法
概述
梯度下降是神经网络中流行的优化算法之一。一般来说,我们想要找到最小化误差函数的权重和偏差。梯度下降算法迭代地更新参数,以使整体网络的误差最小化。

梯度下降是迭代法的一种,可以用于求解最小二乘问题(线性和非线性都可以)。在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法。在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。反过来,如果我们需要求解损失函数的最大值,这时就需要用梯度上升法来迭代了。在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。
该算法在损失函数的梯度上迭代地更新权重参数,直至达到最小值。换句话说,我们沿着损失函数的斜坡方向下坡,直至到达山谷。基本思想大致如图3.8所示。如果偏导数为负,则权重增加(图的左侧部分),如果偏导数为正,则权重减小(图中右半部分) 42 。学习速率参数决定了达到最小值所需步数的大小。
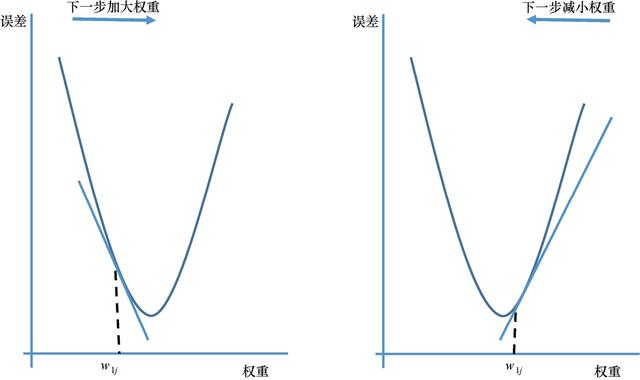
图3.8 随机梯度最小化的基本思想
误差曲面
寻找全局最佳方案的同时避免局部极小值是一件很有挑战的事情。这是因为误差曲面有很多的峰和谷,如图3.9所示。误差曲面在一些方向上可能是高度弯曲的,但在其他方向是平坦的。这使得优化过程非常复杂。为了避免网络陷入局部极小值的境地,通常要指定一个冲量(momentum)参数。
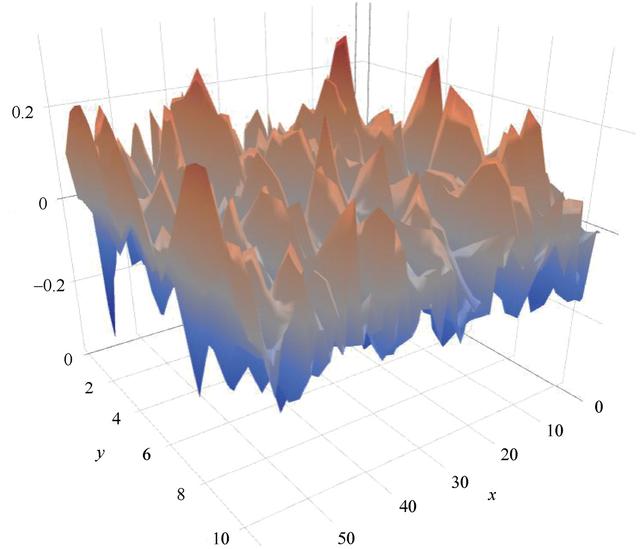
图3.9 典型优化问题的复杂误差曲面
我很早就发现,使用梯度下降的反向传播通常收敛得非常缓慢,或者根本不收敛。在编写第一个神经网络时,我使用了反向传播算法,该网络包含一个很小的数据集。网络用了3天多的时间才收敛到一个解决方案。幸亏我采取一些措施加快了处理过程。
说明 虽然反向传播相关的学习速率相对较慢,但作为前馈算法,其在预测或者分类阶段是相当快速的。
随机梯度下降
传统的梯度下降算法使用整个数据集来计算每次迭代的梯度。对于大型数据集,这会导致冗余计算,因为在每个参数更新之前,非常相似的样本的梯度会被重新计算。随机梯度下降(SGD)是真实梯度的近似值。在每次迭代中,它随机选择一个样本来更新参数,并在该样本的相关梯度上移动。因此,它遵循一条曲折的通往极小值的梯度路径。在某种程度上,由于其缺乏冗余,它往往能比传统梯度下降更快地收敛到解决方案。
说明 随机梯度下降的一个非常好的理论特性是,如果损失函数是凸的 43 ,那么保证能找到全局最小值。
代码实践
理论已经足够多了,接下来敲一敲实在的代码吧。
一维问题
假设我们需要求解的目标函数是:
()=2+1f(x)=x2+1
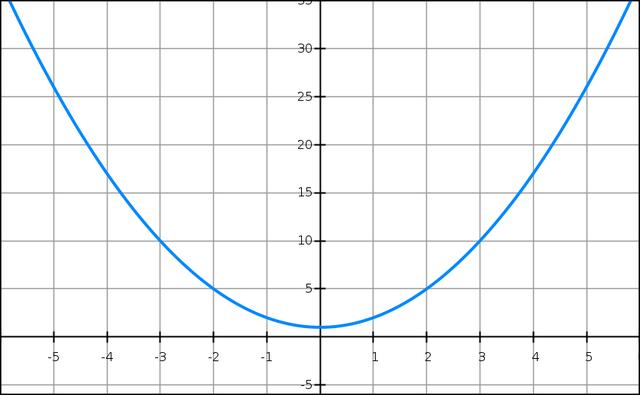
显然一眼就知道它的最小值是 =0x=0 处,但是这里我们需要用梯度下降法的 Python 代码来实现。
- #!/usr/bin/env python
- # -*- coding: utf-8 -*-
- """
- 一维问题的梯度下降法示例
- """
- def func_1d(x):
- """
- 目标函数
- :param x: 自变量,标量
- :return: 因变量,标量
- """
- return x ** 2 + 1
- def grad_1d(x):
- """
- 目标函数的梯度
- :param x: 自变量,标量
- :return: 因变量,标量
- """
- return x * 2
- def gradient_descent_1d(grad, cur_x=0.1, learning_rate=0.01, precision=0.0001, max_iters=10000):
- """
- 一维问题的梯度下降法
- :param grad: 目标函数的梯度
- :param cur_x: 当前 x 值,通过参数可以提供初始值
- :param learning_rate: 学习率,也相当于设置的步长
- :param precision: 设置收敛精度
- :param max_iters: 最大迭代次数
- :return: 局部最小值 x*
- """
- for i in range(max_iters):
- grad_cur = grad(cur_x)
- if abs(grad_cur) < precision:
- break # 当梯度趋近为 0 时,视为收敛
- cur_x = cur_x - grad_cur * learning_rate
- print("第", i, "次迭代:x 值为 ", cur_x)
- print("局部最小值 x =", cur_x)
- return cur_x
- if __name__ == '__main__':
- gradient_descent_1d(grad_1d, cur_x=10, learning_rate=0.2, precision=0.000001, max_iters=10000)
就是这么酷吧!用Python理解剃度下降!
更多信息来自:东方联盟网 vm888.com
- 02-23人工智能和python之间有什么联系?为何用python?
- 03-022021年值得关注的人工智能趋势
- 03-02人工智能和物联网——5个新兴的应用案例
- 03-02人工智能将使纺织工业的生产过程实现数字化和自动化
- 03-02如何应对人工智能在医疗保健领域的挑战
- 07-21人工智能、物联网和大数据如何拯救蜜蜂


- 01-11全球最受赞誉公司揭晓:苹果连续九年第一
- 12-09罗伯特·莫里斯:让黑客真正变黑
- 12-09谁闯入了中国网络?揭秘美国绝密黑客小组TA
- 12-09警示:iOS6 惊现“闪退”BUG
- 04-21中国产品数字护照体系加速建设
- 04-21上海口岸汽车出口突破50万辆
- 04-21外媒:微软囤货GPU以发展AI
- 04-21苹果手表MicroLED项目停滞持续波及供应链
- 04-21三部门:到2024年末IPv6活跃用户数达到8亿














 粤公网安备 44060402001498号
粤公网安备 44060402001498号