数据库优化五 SQL优化之SELECT优化 order by 优化
在使用sql查询数据库的数据时,经常会使用到排序的操作,因此,如果对于排序的
数据,不能用到索引,将是一个很好时间的事情,数据库的解决方法有两个:1、选择
完所有行后,数据较少,用内存来排序;2、数据较大,用硬盘文件排序,这将很耗时,
特别影响性能。
而如果能运用好索引,则会少很多排序的消耗,因为当使用排序时,只根据索引
去顺序读取,然后发送到客户端。
1、当使用排序时,复合索引不需要额外排序的情形
a、对于复合索引时,最前面的列在排序字段中
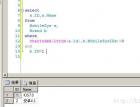
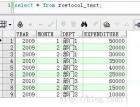
SELECT * FROM t1 ORDER BY key_part1,key_part2,...
b、排序的字段不是复合索引的第一个,但where条件包含第一个且为常量
SELECT * FROM t1 WHERE key_part1 = constant ORDER BY key_part2;c、只使用到复合索引的第一个列
SELECT * FROM t1 WHERE key_part1 > constant ORDER BY key_part1 ASC;
注:对于复合索引,如果要排序,能用到索引,必须用到复合索引的第一个字段才可以
2、以下情形,用不到索引,用额外的排序a、使用不同的索引
SELECT * FROM t1 ORDER BY key1, key2;b、只使用到部分的复合索引,但不是复合索引的第一个列
SELECT * FROM t1 WHERE key2=constant ORDER BY key_part2;c、对复合索引,同时有升序和降序
SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC;d、对于要获取的行的筛选条件和排序条件不一致时
SELECT * FROM t1 WHERE key2=constant ORDER BY key1;e、对于排序的列上,还加有其他的函数处理,打乱了原来索引的顺序
SELECT * FROM t1 ORDER BY ABS(key);SELECT * FROM t1 ORDER BY -key;f、当jion了很多表时,order by后面的字段不是所有的列都来自第一个非
常量表中的索引字段,(第一个非常量表为在EXPLAIN中第一个不是
type为const的类型的表),因为排序只能根据一个表的字段排序,不
能跨表排序
g、使用不同的group by 和order by语句,其实,当你使用group by 语句时
他已经给你排序了。
建议,当数据很大的时候,写group by时,对数据的顺序不关心时,加
上一个order by null减少排序的操作
h、如果使用的排序字段的前面的一部分,也不能用到排序索引,这种情况下
经常会使用文件排序filesort,如有一个字段char(20),但只对前面的10个字节
做了索引了,那么直接排序时,将使用文件排序来达到正确排序
i、使用hash索引时也无法排序使用
j、当对一个索引列重命名后为原来的名字,但后面友想以此来排序,也不能
使用索引,如:
SELECT ABS(a) AS a FROM t1 ORDER BY a;原因是:order by 找的字段优先考虑重select的字段查找,然后查找表的字段
由于做了别的运算,导致索引已经无法使用了
但改为别的名字就可以用了,如:
SELECT ABS(a) AS b FROM t1 ORDER BY a;
>更多相关文章
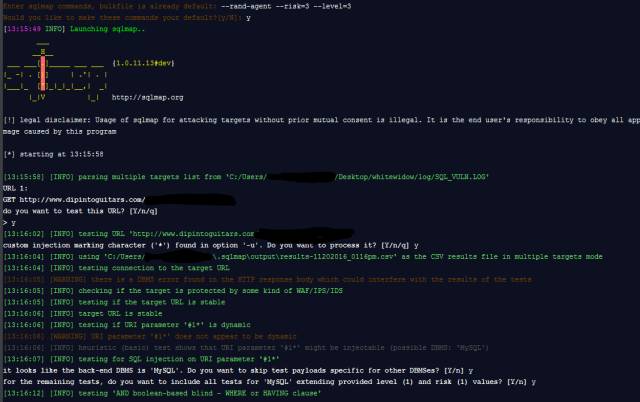
- 10-26Whitewidow SQL漏洞扫描工具演示
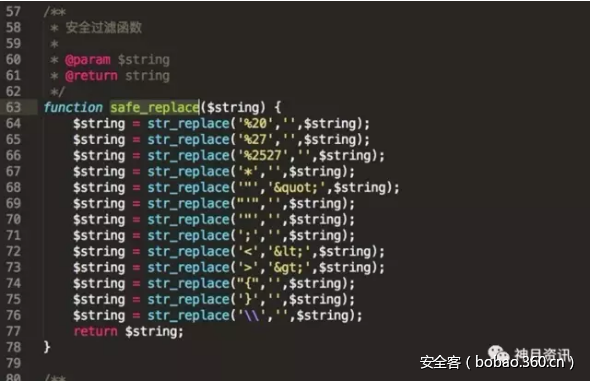
- 10-26SQL黑客注入防御与绕过的多种姿势
- 12-23SQLServer数据库操作总结(sql语法的使用)
- 12-21C#连接Sqlite
- 12-21ORACLE数据库学习之SQL性能优化详解
- 12-21解决SQLSERVER2008数据库日志文件占用硬盘空间问题
首页推荐
佛山市东联科技有限公司一直秉承“一切以用户价值为依归
- 01-11全球最受赞誉公司揭晓:苹果连续九年第一
- 12-09罗伯特·莫里斯:让黑客真正变黑
- 12-09谁闯入了中国网络?揭秘美国绝密黑客小组TA
- 12-09警示:iOS6 惊现“闪退”BUG
- 06-01星环科技加码AI基础设施业务布局 发布知识平
- 06-01天猫618:淘宝商家报名数同比增长24%
- 06-01饿了么品牌升级焕新:经营进入新周期 将坚持
- 06-01报告:技术创新对打造可持续影响力企业尤为
- 05-30腾讯应用宝将在Microsoft Store上架 Wind
相关文章
![[SQLServer]发送HTML格式邮件](/d/file/database/SQLServer/2013-12-21/e4cf8ee11e5808af02776facb796ca42.jpg)

24小时热门资讯
24小时回复排行
热门推荐
最新资讯



操作系统
黑客防御



 粤公网安备 44060402001498号
粤公网安备 44060402001498号