十五个点,理解Apache Kafka
一、介绍
Kafka在世界享有盛名,大部分互联网公司都在使用它,那么它到底是什么呢?

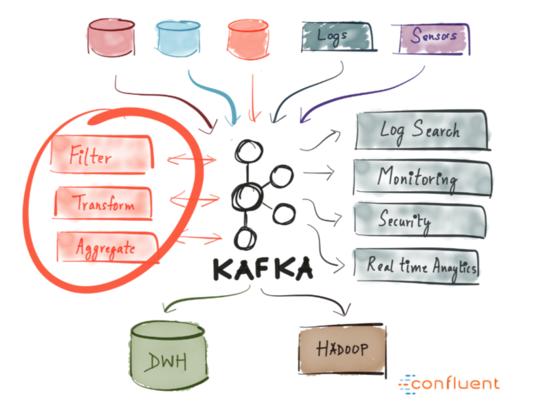
Kafka由LinkedIn公司于2011年推出,自那时起功能逐步迭代,目前演变成一个完整的平台级产品,它允许您冗余地存储巨大的数据量,拥有一个具有巨大吞吐量(数百万/秒)的消息总线,并且支持实时流任务处理。总的来说,Kafka是一个分布式,可水平扩展,容错的日志提交系统
这些描述都非常抽象,让我们一个接一个地理解它们的意思,随后深入探讨其工作原理。
二、分布式
分布式系统意味着不同机器上的服务实例一起工作成一个整体为用户提供完整的服务,Kafka的分布式体现在存储、接收信息、发送信息在不同的节点上,它带来的好处是可扩展性和容错性。
三、水平可扩展
我们先给垂直可扩展下一个定义,比如说,你的传统数据库服务开始变得超负载,可以通过简单地扩充该服务器资源(CPURAMSSD)缓存这个问题,这就叫垂直扩展-单点增加资源,不过有两大致命的缺点:底层硬件资源有限、需要停机操作。反之,水平扩展通过增加更多的机器部署服务解决类似问题。
四、容错
分布式系统被设计成可容许一定程序的错误,不像单点部署发生异常时整体服务都将不可用,有五个节点的Kafka实例,即使有2个节点宕机了仍能继续工作。
五、commit日志
一个commit日记类似预写式日记(WAL)和事务日记,它是可追加的有序的持久化数据,无法进行修改或者删除。
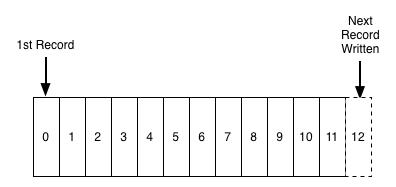
这种结构是Kafka的核心,它具备排序功能,而排序则可以保证确定性的处理,这两者都是分布式系统中的重要问题。
Kafka通常会将消息持久化到磁盘上,它充分利用磁盘的有序读取特性,读写的时间复杂度都为O(1),这是相当了不起的,另外读取和写入操作不会相互影响,写入不会加锁阻塞读取操作。
六、如何工作的
生产者发到消息至Kafka Node节点,存储在主题Topic中,消费者订阅主题以接收消息,这是一个生产订阅模式。为了使一个节点Topic的数据量不至过大,Kafka引入分区的概念,从而具备更好的性能和伸缩性。Kafka保证分区内的所有消息都按照到达顺序排序,区分消息的方式是通过其偏移量offset,你可以将其理解为普通数组的下标索引。
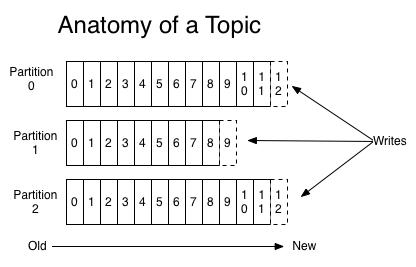
Kafka中Broker服务节点是愚蠢的,消费者是聪明的,Kafka不会记录消费者读取的操作和删除消息,相反,数据被存储一段时间或者达到一定的大小阈值,消费者可以自由调整偏移量offset以重复获取他们想要的消息或者舍弃。
值得注意的是为了避免进程两次读取相同的消息,Kafka引入了消费者组的概念,其中包含一个或者多个消息者实例,约定每个组只能同时有一个实例消费分区的消息。不过这引来了一个麻烦,连社区也无力解决,也就是Kafka中的重平衡Rebalance问题,它本质是一种协议,规定一个消费者组下的所有消费者实例如何达成一致,来分配订阅主题的每个分区,当组成员数发生变更、订阅主题数发生变更、订阅主题的分区数发生变更时都会触发Rebalance,从而达到最公平的分配策略,不过他和GC的STW类似,在Rebalance期间,所有的消费者实例都会停止消费,然后重新分配连接。我们应该尽量避免这种情况的发生,尽量让消费实例数等于分区数。
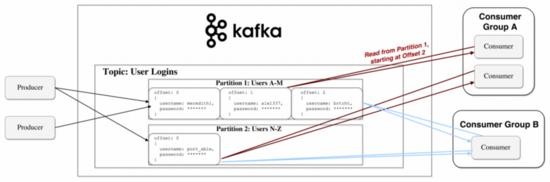
七、持久化至磁盘
正如前面提及的,Kafk将消息存储至磁盘而不是内存RAM,你或许会惊讶它是如何做出这种选择的,背后应该有许多优化使其可行,没错,事实上优化点包括:
- Kafka的通信协议支持消息合并,减少网络流量传输,Broker节点一次持续存储大量数据,消费者可以一次获取大量的消息
- 操作系统通过提前读入(read-ahead)和write-behind缓存技术,使得磁盘上的线性读写速度快,现代磁盘速度慢的结论是基于需要磁盘搜索的场景
- 现代操作系统引入页面缓存(Page cache)技术,页缓冲由多个磁盘块构造,在linux读写文件时,它用于缓存文件的逻辑内容,从而加块对磁盘映射和数据的访问
- Kafka存储消息使用的是不可变的标准二进制格式,可以充分利用零拷贝技术(zero-copy),将数据从页缓存直接复制到socket通道中
八、数据分布式和复制
我们来谈谈Kafka如何实现容错以及如何在节点间分配数据。
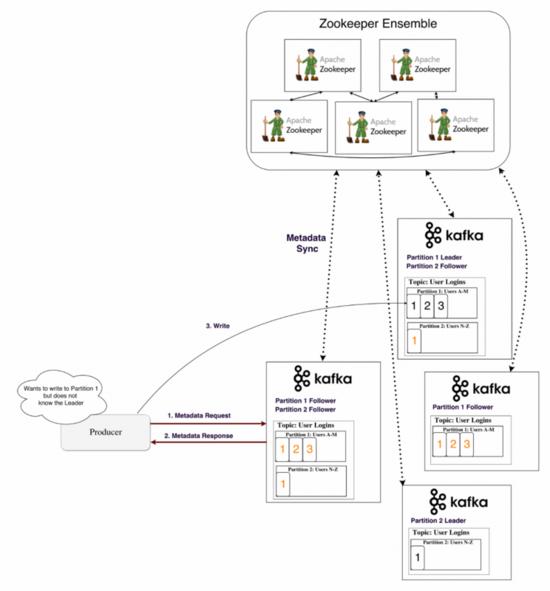
Kafka将分区数据拷贝复制到多个Brokers节点上,避免某个Broker死亡导致数据不可达。每时每刻,一个Broker节点”拥有”一个分区,并且是应用程序从该分区读取写入的节点,这称为分区leader,它将收到的数据复制到其他N个Broker节点上,它们称为follower,并准备好在leader节点死亡时被选举为leader。这种模式使得消息不易丢失,你可以根据消息的重要程序合理调整replication factor参数,下图是4个Broker节点,拥有3个复制副本的示例:
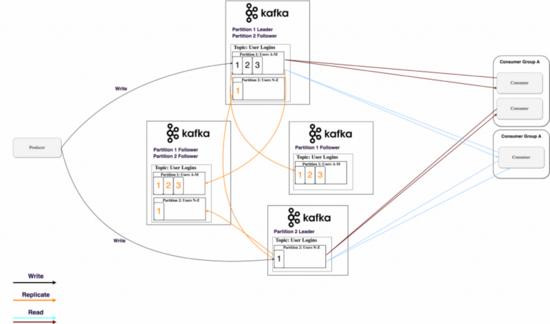
你或许会有疑问,生产者或者消费者是如何正确得知分区的leader是哪个节点的?事实上,Kafka将这些信息保存到Zookeeper服务中。
九、Zookeeper服务
Zookeeper是一个分布式KV对目录存储系统,特点是可靠性高、读取性能高,但是写入性能差,常被用于存储元数据和保存集群状态,包括心跳、配置等等。
Kafka将以下消息保存至Zookeeper中:
- 消费者组的每个分区的偏移量,不过后来Kafka将其保存至内部主题__consumer_offsets中
- 访问权限列表
- 生产者和消费者速率限定额度
- 分区leader信息和它们的健康状态
十、Controller控制器
一个分布式系统肯定是可协调的,当事件发生时,节点必须以某种方式做出反应,控制器负责决定集群如何做出反应并指示节点做某事,它是功能不能过于复杂的Broker节点,最主要的职责是负责节点下线和重新加入时重平衡和分配新的分区leader。
控制器从ZooKeeper Watch事件中可以得知某个Broker节点实例下线(或者节点过期,一般发生于Broker长时间繁忙导致心跳异常)的情况,然后做出反应,决定哪些节点应成为受影响分区的新leader,然后通知每个相关的follower通过leaderAndlsr请求开始从新的leader复制数据。
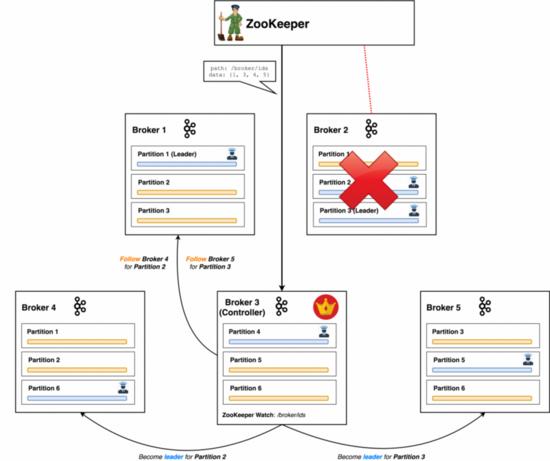
从上面可以得知,原本作为分区leader的Broker节点实例重启后,它将不再担任任何分区的leader,消费者也不会从这个节点上读取消息,这导致了资源的浪费,幸运的是,Kafka有一个被称为优先副本(preferred leader replica)的概念-你可以理解成原先为该分区leader节点(通过broker id区分)的副本,如果该副本可用,Kafka会将集群恢复成之前状态,通过设置auto.leader.rebalance.enabled=true可以使得这个过程自动触发,默认值为true。
Broker节点下线通常都是短暂的,这意味着一段时间后会恢复,这就是为什么当一个节点离开集群时,与之关联的元数据不会被删除,如果它是一个分区的跟随者,系统也不会为此分区重新分配新的跟随者。
但是需要注意的是,恢复加入的节点不能立即拿回其上次的leader地位,它还没有资格。
十一、ISR
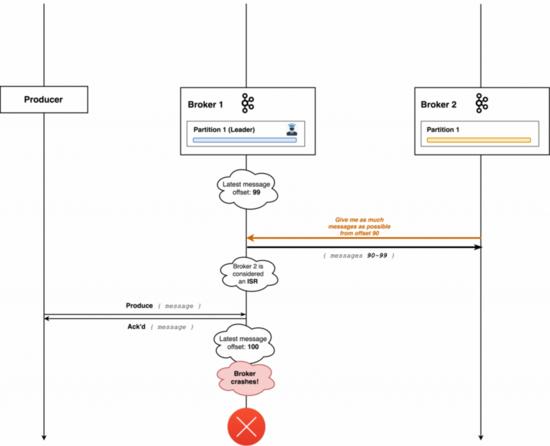
副本同步队列ISR(in-sync replicas),它是由leader维护的,follower从leader同步数据是有延迟的,任意一个超过阈值都会被剔除出ISR列表, 存入OSR(Outof-Sync Replicas)列表中,新加入的follower也会先存放在OSR中。
一个follower想被选举成leader,它必须在ISR队列中才有资格,不过,在没有同步副本存在并且已有leader都下线的边缘情况下,可以选择可用性而不是一致性。
ISR列表维护标准如下:
- 它在过去的X秒内有完整同步leader消息,通过replica.lag.time.max.ms配置约定
- 它在过去的X秒内向Zookeeper发送了一个心跳,通过zookeeper.session.timeout.ms配置约定
十二、生产者acks设置
明显,存在一系列意外事件会导致leader下线,假如leader节点接收到生产者的消息,在存储并且响应ack后节点崩溃了,此时Kafka会从ISR列表中选举一个新的leader,但是由于生产者ack配置默认为1,意思是只考虑leader接收情况不考虑follower同步情况,最终导致部分消息丢失了,所以我们应该在生产者端设置acks=all,要求每条数据必须是写入所有副本之后,才能认为是写成功,另外一层意思是起码有一个leader和一个follower。不过这种设置影响集群性能,降低了吞吐量,使得生产者需要在发送下一批消息之前等待更多时间。
十三、水位
通过ack=all约定了leader节点在消息没有同步到所有的ISR列表前不会有任何返回,另外,节点会跟踪所有同步副本具有的最大偏移量,也就是高水位偏移量HW(high watermark offset),consumer无法消费分区下leader副本中偏移量大于分区HW的任何消息。当某个副本成为leader副本时、broker出现崩溃导致副本被踢出ISR时、producer向leader写入消息后、leader处理follower fetch请求时,都会尝试更新分区HW,从而保证了数据一致性和正常消费时不会出现读取到旧值。

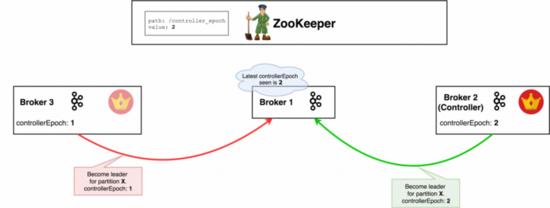
十四、脑裂
想象一下,当正常存活的controller控制器由于长时间GC-STW导致不可用,然后Zookeeper会认为/controller节点(节点3)已经过期随即删除并发送通知到其他broker节点,其他每个broker节点都尝试升级为控制器节点,假设节点2从竞争中胜出成功新的控制器节点并在ZK中创建/controller节点。
然后其他节点接收到通知,了解到节点2成为了新的控制器节点,除了还在GC暂停的节点3,或者通知压根没到达的节点3,也就是说节点3不知道leadership已经发生了变化,它还以为自己是控制器节点。此时,同时存在两个控制器,并行发出可能存在冲突的命令,导致严重的后果。
幸运的是,Kafka提供了epoch number的方式可以轻松区分出真实的控制器,它是自增长的序列号,信息存储在ZooKeeper中,显然序列号最大的那个节点才是真实的。
十五、什么时候应该使用Kafka
从上面几点可知,Kafka可以成为事件驱动架构的中心部分,使你可以真正将应用程序彼此分离。
更多信息来自:东方联盟网 vm888.com
- 11-06Hadoop是目前大数据领域最主流的一套技术体系
- 11-06大数据和人工智能:三个真实世界的用例
- 11-06为什么说,大数据与行业专家是“共生”关系?
- 11-06Python数据可视化:箱线图多种库画法
- 11-06这种思路讲解HDFS你肯定没见过?快速入门Hadoop必备
- 11-06媲美Pandas的数据分析工具包Datatable

- 01-11全球最受赞誉公司揭晓:苹果连续九年第一
- 12-09罗伯特·莫里斯:让黑客真正变黑
- 12-09谁闯入了中国网络?揭秘美国绝密黑客小组TA
- 12-09警示:iOS6 惊现“闪退”BUG
- 05-15奇安信:数据安全问题是医疗卫生行业数字化
- 05-15腾讯宣布混元文生图大模型开源
- 05-15网易云音乐与韩国知名娱乐公司Kakao达成战略
- 05-15阿联酋宣告正式开启“5G-A全国商用”计划,
- 05-15二十年未遇的强烈地磁暴来袭













 粤公网安备 44060402001498号
粤公网安备 44060402001498号